Sequence labels indicate KO, taxonomy or model organism, organism name (if taxonomic group), and gene name, respectively. CEL, C. elegans; HSA, H. sapiens; DME, D. melanogaster; ATH, A. thaliana; SCE, S. cerevisiae; BAC, bacteria; ARC, archaea; PRO, protists; FUN, fungi; PLA, plants; INV, invertebrates; NEM, nematodes; ART, arthropods; VER, vertebrates; MAM, mammals. Parenthetical information for organisms other than CEL indicates whether the genes are introduced as best matches (B) or reciprocal best hits (R) to the query gene. Parenthetical information for CEL indicates whether the genes are introduced as paralogues (P) of the query gene or as reciprocal best matches to one of the other organisms in the tree (B). Organism abbreviations are from KEGG.
The information and tools provided in this website are to be used for academic purposes only.




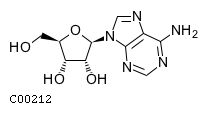
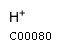
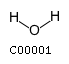
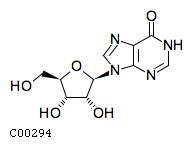
Comments