


| ID - Confidence | |
|---|---|
| KO | K14085 - High |
| Enzyme |
1.2.1.31 - High 1.2.1.3 - High 1.2.1.8 - High |
| Reaction |
R02940 - High R04903 - High R03869 - High R02957 - High R04863 - High R04390 - High R03283 - High R05050 - High R02549 - High R04506 - High R02678 - High R04065 - High R03102 - High R03103 - High R02565 - High R02566 - High R00631 - High R00710 - High R01986 - High R00904 - High R01752 - High R03098 - High |
| ID - Confidence | |
|---|---|
| KO | ERROR |
| Enzyme | ERROR |
| Reaction | ERROR |
Comments

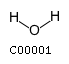
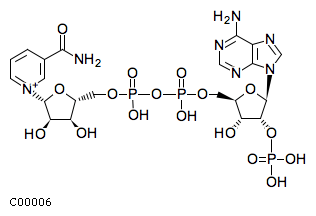

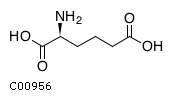
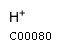
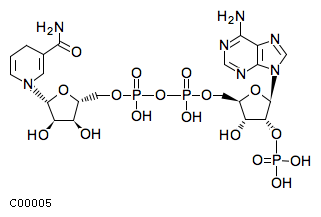
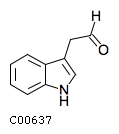
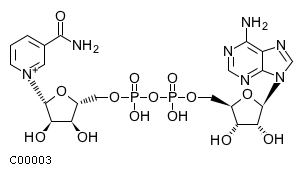

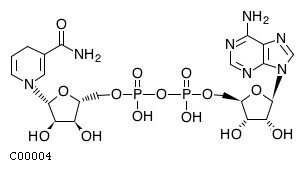
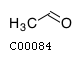
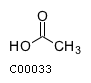
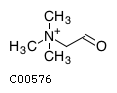
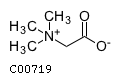
Comments